VibeSkills:一个让你解放大脑,端到端的Skills路由器
很多人第一次看到 VibeSkills,会把它当成“另一个大而全的 skills 仓库”。
但如果把它当成纯技能集合,会低估它真正想解决的问题。
在我的理解里,VibeSkills 的核心目标不是“堆更多工具”,而是把 AI 协作从“凭感觉调用工具”升级为一条可治理、可验证、可复用的交付流程。

先说结论
VibeSkills 本质上是在做一层运行时治理:
- 先通过
Canonical Router解决“该调用谁”。 - 再通过
M / L / XL分级解决“该怎么执行”。 - 最后通过治理规则与证据产物解决“做到什么才算完成”。
所以它的价值并不止于“会调用很多 skill”,而在于把多工具、多步骤、多代理协作收进统一执行法则。
一、VibeSkills 在解决什么真实痛点
如果你是重度 AI 编码用户,应该都遇到过这些问题:
- 装了很多技能,但模型经常想不起来触发。
- AI 直接开做,没有澄清边界,结果偏题后返工。
- 插件和工作流之间缺少统一约束,容易冲突。
- 长任务跨会话或换 agent 后,历史上下文断裂。
- 交付时缺少证据链,结果难以复核、难以交接。
VibeSkills 的做法不是继续叠工具,而是把这些问题统一抽象成三件事:
- 调度问题:路由与冲突裁决。
- 治理问题:流程约束与风险边界。
- 记忆问题:跨阶段、跨会话上下文延续。
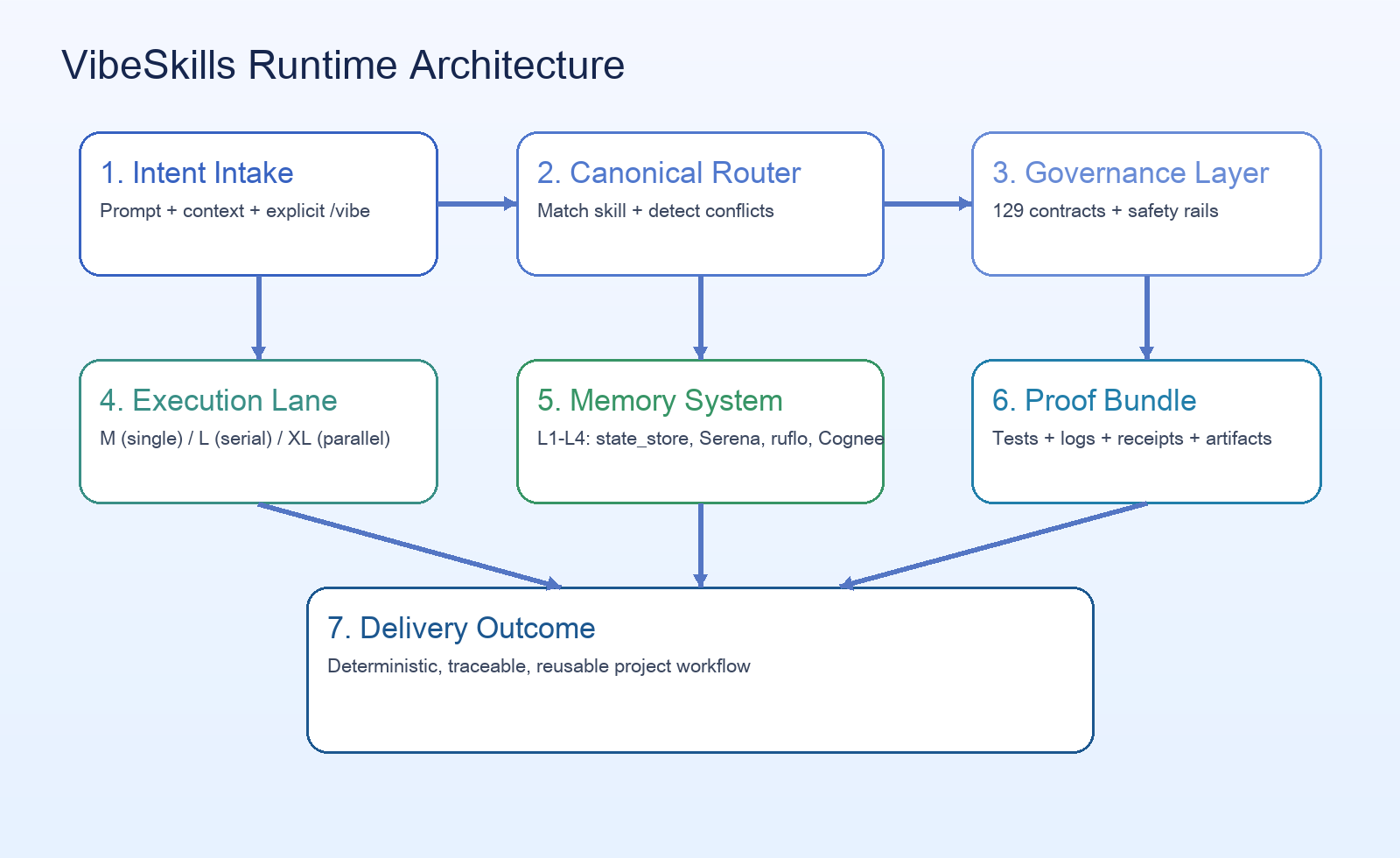
二、核心机制:为什么它看起来更“稳”
1. Canonical Router:先决定“谁来做”
VibeSkills 的路由思路是“单一主路由 + 受管协同子技能”:
- 识别任务意图与复杂度。
- 匹配主技能并做冲突检测。
- 按优先级裁决执行路径。
- 主技能可调用子技能,但不允许抢占流程控制权。
这比“模型想到哪个就用哪个”更可预测,尤其在复杂任务里更稳定。
2. M / L / XL 执行分级:再决定“怎么做”
主技能确定后,再按任务复杂度进入不同执行级别:
M:小任务、单代理、强调速度。L:中等复杂度,按计划串行推进。XL:大任务,支持多代理并行分波执行。
这层分级的意义是避免两种常见错误:
- 小任务过度工程化。
- 大任务却沿用一次性直推,最终失控。
3. 治理契约:最后决定“什么叫完成”
VibeSkills 文档中强调了较完整的治理规则集(公开信息里提到 129 条契约/策略),它的工程价值在于:
- 把高风险操作纳入显式边界。
- 约束阶段切换,降低“跳步骤抢跑”。
- 要求输出可审计证据(测试、日志、产物、清理记录等)。
换句话说,它不是“更会说”,而是“更难糊弄”。
三、与同类项目相比,它的优势在哪
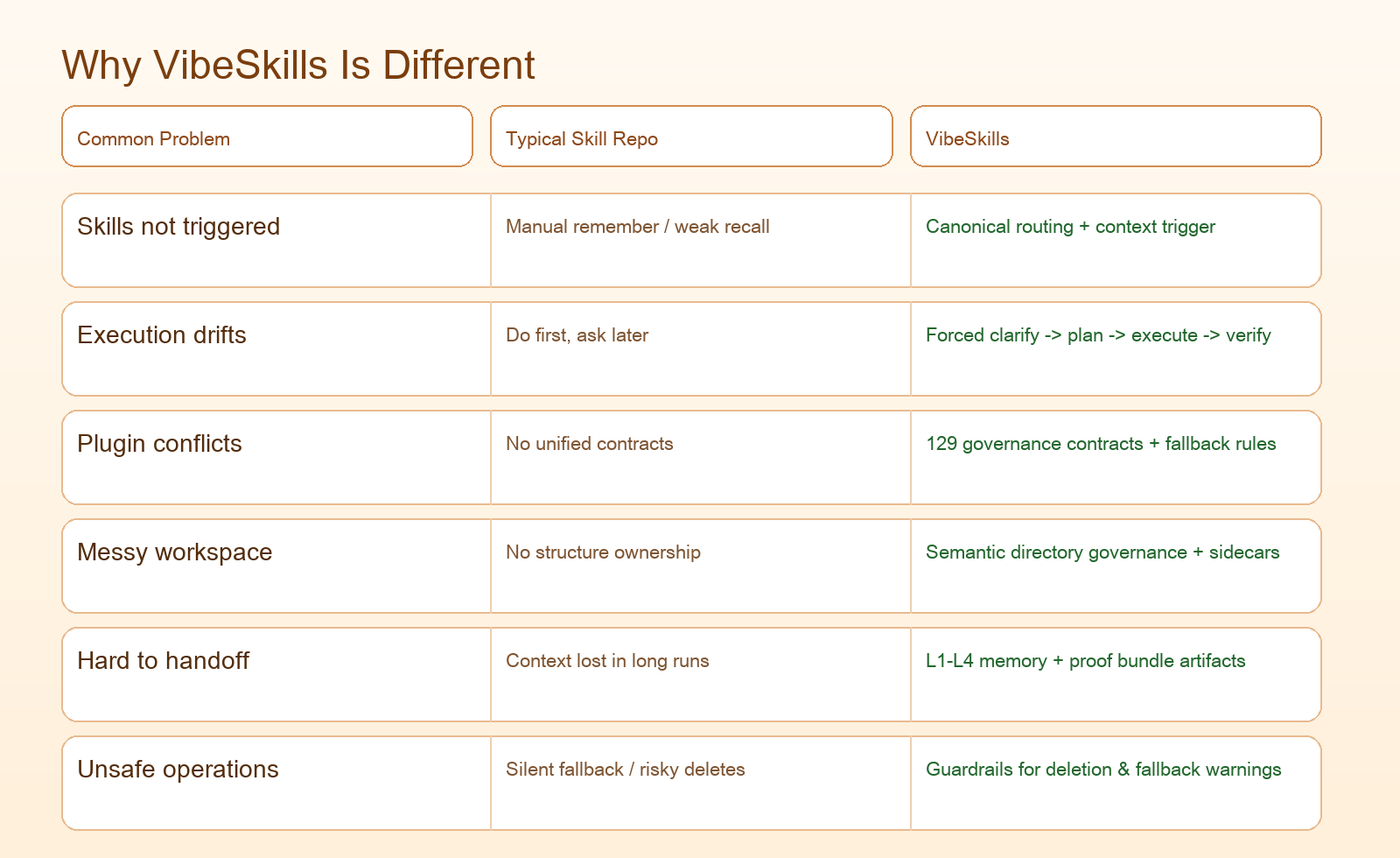
如果按工程落地视角看,VibeSkills 的差异点大致是:
| 对比维度 | 传统 skills 集合 | 单点流程框架 | VibeSkills |
|---|---|---|---|
| 入口体验 | 技能多,但触发依赖记忆 | 仅某环节强 | 单入口运行时,强调端到端串联 |
| 调度逻辑 | 常见“谁先想到谁” | 多为局部策略 | Canonical Router + 冲突裁决 |
| 流程治理 | 依赖个人纪律 | 覆盖局部流程 | 澄清-规划-执行-验证闭环 |
| 长任务连续性 | 易丢上下文 | 依赖外部拼接 | 明确分层记忆设计 |
| 多 Agent 协同 | 常见临时拼装 | 受限于框架能力 | 运行时角色分层与流程约束 |
| 可审计性 | 经常只看结果 | 需额外补日志 | 强调 proof bundle 与留痕 |
也要客观看:
- 它并不是替代所有工具。
- 它更像把多个优秀上游能力(如 spec-kit、serena、scrapling、claude-flow 等)放进统一治理底座里。
四、项目现状与活跃度(截至 2026-04-10)
基于公开仓库元数据:
- Stars:1339
- Forks:104
- Open Issues:8
- License:Apache-2.0
- 创建时间:2026-02-22
- 最近推送:2026-04-10(UTC)
这说明它还很新,但迭代节奏明显偏快,属于高活跃演进期。
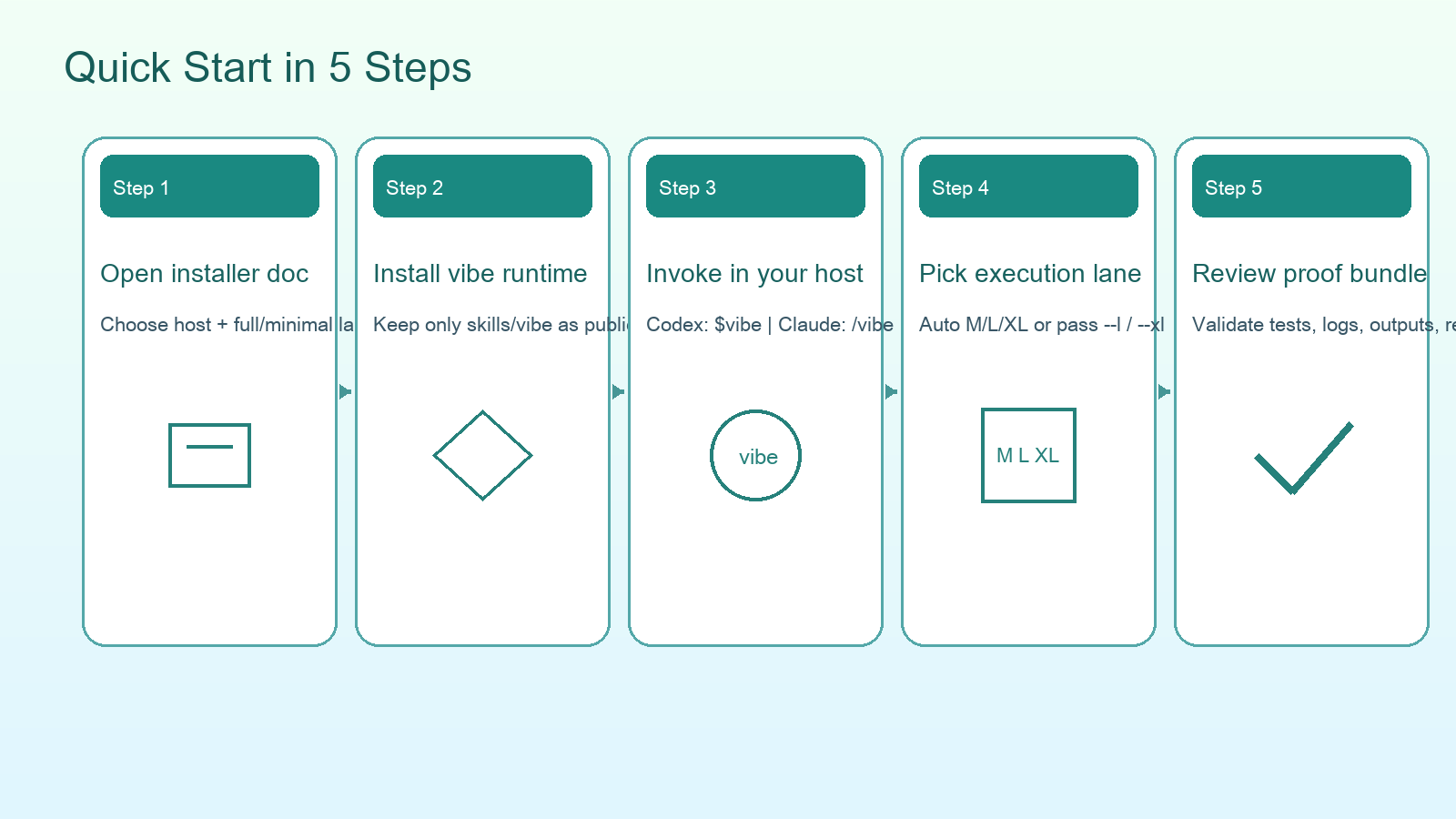
五、如何在你的工作流里上手
1. 先确认宿主环境
当前公开说明里可见支持或适配的环境包括:
- Codex
- Claude Code
- Cursor
- Windsurf
- OpenClaw
- OpenCode
注意它是 Skills 调用架构,不是一个独立 CLI 二进制心智模型。
2. 使用方式(最小可行)
官方示例通常是:
- Claude Code:
/vibe - Codex:
$vibe
例如:
1 | 我希望你设计一个新的支付结算模块,先澄清需求再给出计划并执行验证 $vibe |
3. 复杂任务建议
如果任务是跨模块、跨文件、跨阶段的大改动,建议显式要求:
- 先冻结需求范围。
- 输出执行计划与分阶段检查点。
- 强制产出验证证据(tests/logs/artifacts)。
- 长任务中途做上下文折叠再交接。
六、它适合谁,不适合谁
更适合
- 已经重度依赖 AI 开发,开始遇到规模化协作混乱的人。
- 需要多阶段、多角色、多工具编排的人或团队。
- 关注稳定交付和可追溯性,而非“单次最快结果”的场景。
不太适合
- 只想跑一个轻量脚本,做完即走。
- 不关心过程治理与可审计证据。
- 任务长期都非常短平快,复杂运行时收益不明显。
七、常见问题(FAQ)
Q1:技能这么多,会不会上下文爆炸?
它的思路是路由触发,不是全量展开;但治理本身确实有开销,因此更适配中大任务。
Q2:/vibe 或 $vibe 等于 MCP 已装好吗?
不是。它代表受管运行时入口,不等于宿主原生 MCP 配置已完成。
Q3:我可以只用它一部分能力吗?
可以。公开文档里提供了不同安装/能力层级路径,可按实际需求选择。
Q4:为什么它反复强调 proof bundle?
因为“模型说完成”并不构成交付证据。工程交付必须可复核、可追踪、可交接。
八、总结
VibeSkills 的价值不在“能不能写代码”,而在它回答了一个更关键的问题:
当 AI 从辅助问答走向真实生产协作时,我们如何保证质量、连续性和可控性。
如果你正从“玩模型”切到“用模型交付”,它值得你认真跑一轮真实任务。
参考链接
 wechat
wechat alipay
alipay