AI 中转站连续三天故障复盘:不是业务打爆机器,而是 Ubuntu/KVM 生产机 soft lockup
这几天 AI 中转站连续出问题,我先把话说在前面:这次影响到正常使用的用户,是我们的责任。
前两天是生产服务器每天瘫一次,第三天是服务商官方维护。对用户来说,不管背后的原因是什么,结果都是这几天服务不稳定。这个体验很差,我自己也很烦。
所以技术复盘之外,我们也做了补偿:
- 对这几天受影响的使用做了倍率下调。
- 给部分受影响用户补发了额度。
- 发放了后续可用的优惠券。
补偿不是为了把事情糊过去。服务不稳定就是不稳定,该补的补,该查的也要查清楚。
这篇文章主要讲后半部分:为什么我最后判断,前两天的崩溃不像是 sub2api 业务单纯把机器打爆,而是 Ubuntu/KVM 生产机在内核、虚拟磁盘 I/O、journald、Docker 日志和 UFW 日志刷屏叠加下触发了系统级 soft lockup。
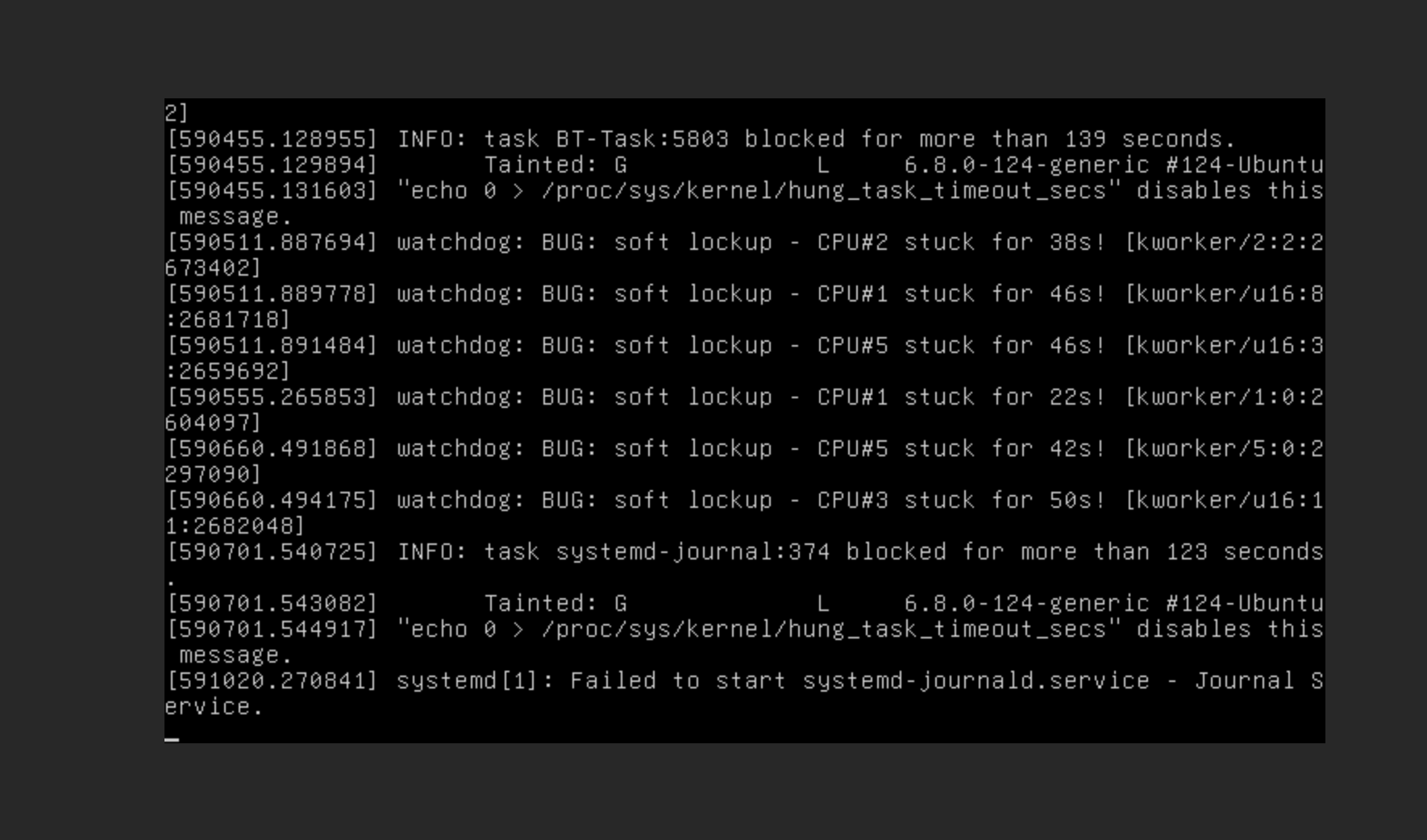
VNC 上能看到的核心日志大概是这样:
1 | watchdog: BUG: soft lockup - CPU#6 stuck for 40s! [kworker/u16:8:415303] |
当时的状态不是“接口慢一点”,而是机器接近失联:
- SSH 基本连不上。
- AI 中转站业务无法正常响应。
- Docker 容器 healthcheck /
exec大量 timeout。 - VNC 还能显示内核日志,但系统已经卡得很深。
systemd-journald被阻塞,并且反复启动失败。
一开始我也按最普通的方向想:是不是业务流量上来了,容器把 CPU 或内存吃满了?
但往下查之后,这个判断站不住。
第三天是服务商维护,但用户感知上还是连续故障
第三天的不可用,后来从工单确认是官方维护。
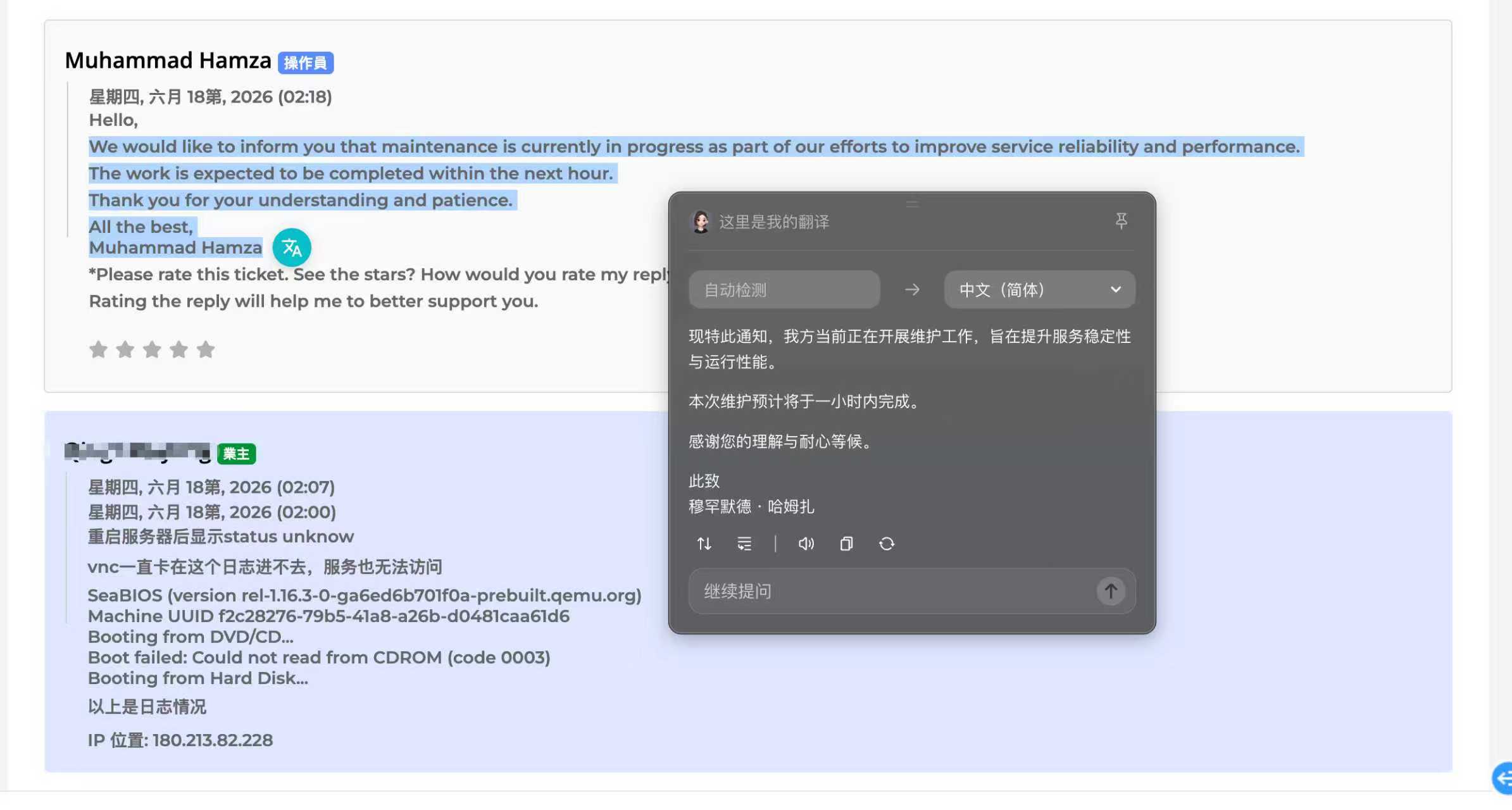
工单里说得很明确:维护正在进行,目的是提升服务可靠性和运行性能,预计一小时内完成。
所以从技术原因上,要分成两件事:
- 前两天:我的生产虚拟机系统级卡死。
- 第三天:服务商官方维护。
但我不想拿这个做借口。用户不会关心“今天是内核问题,明天是服务商维护”。用户只会记得:连续几天不稳定。
所以补偿和修复是一起做的。补偿解决这几天造成的使用损失;修复解决后面不要反复出同样的问题。
这台 AI 中转站机器其实很简单
机器配置如下:
- 系统:Ubuntu 24.04.4 LTS
- 环境:KVM/QEMU 虚拟机
- CPU:8 核
- 内存:约 16GB
- 主要业务:Docker 里的
sub2apiAI 中转站 - 相关组件:Postgres、Redis
这台服务器没有跑一堆乱七八糟的东西,主要就是 AI 中转站这一套。所以它崩的时候,我最先看的是几个很朴素的指标:
- 磁盘是不是满了?
- inode 是不是满了?
- 内存是不是被吃爆了?
- 有没有明显的业务进程把 CPU 打满?
结果都不是特别符合。
磁盘空间没耗尽,inode 没耗尽,内存整体也没被打爆。业务当然有压力,但现场最怪的不是业务进程忙,而是系统任务也卡住了。
真正让我改变判断的是这些信号:
kworker卡住。systemd-journalblocked 超过 122 秒。- 内核报
soft lockup。 - Docker
exec/ healthcheck 大面积 timeout。 - 历史调用栈里出现
ext4_sync_file、jbd2_journal_force_commit、fdatasync。
这几个东西放在一起,就不像单纯应用层问题了。
如果只是业务代码有 bug,通常会看到业务进程 CPU 高、内存高、连接堆积、数据库慢查询。可这次更像是系统写盘同步链路被拖住,连 journald 和 kworker 都一起掉进去了。
所以我现在更倾向于认为:journald 启动失败不是根因,它只是底层 I/O 或内核卡住后最明显的受害者。
我把问题拆成了几层看
1. 故障都落在 6.8.0-124-generic 上
前两天事故都发生在 6.8.0-124-generic。
我不会只凭一个版本号就说“内核背锅”。但当 soft lockup、kworker stuck、systemd-journald blocked 一起出现时,问题已经越过了普通容器故障的范围。
soft lockup 不是 CPU 使用率高这么简单。它更像是某个 CPU 长时间卡在内核态,调度迟迟切不出来。对生产机来说,这比某个接口慢更麻烦,因为整个系统都有可能开始失去响应能力。
2. ext4 / jbd2 / fdatasync 指向写盘同步链路
历史日志里出现过:
1 | ext4_sync_file |
这几个词基本都在提醒我:系统可能卡在 ext4 文件系统日志提交、磁盘同步这条路径上。
这里不能说死。它不等于“ext4 一定有 bug”,也不等于“磁盘一定坏了”。但至少说明排查方向不能只停留在业务容器里。
3. Docker JSON 日志变成了放大器
sub2api 容器的 Docker JSON 日志曾经涨到约 1.2G。
Docker 默认的 json-file 如果不配轮转,日志会一直写。平时看起来只是占磁盘,但系统一旦抖动,巨型日志文件、持续写入、journald、kernel log、healthcheck timeout 会叠在一起。
这时候日志就不是单纯记录问题,而是在参与问题。
4. UFW 日志被公网扫描刷屏
公网服务器每天都会被扫,这个很正常。
但 UFW logging 打开后,大量 [UFW BLOCK] 会进入 kernel log / journald。平时只是烦,故障时就是压力。
我这次最大的教训之一就是:生产机器上,没必要的防火墙日志不要一直开着。它看起来像“多留点证据”,但在 I/O 抖动时可能就是多加一脚油门。
5. KVM 虚拟机本身也不能当背景板
这台机器是 KVM/QEMU 虚拟机,历史日志里还出现过 clocksource skew。
这个信号不等于宿主机一定有问题,但它让我不能把虚拟化层当成完全透明。
尤其当你同时看到:
clocksource skewkworker soft lockupext4/jbd2/fdatasync- journald blocked
- Docker healthcheck timeout
就要把宿主机调度、虚拟磁盘 I/O、存储后端和内核版本一起纳入怀疑范围。
我的判断:这不是一个单点故障
我现在的判断是:
前两天 AI 中转站生产机崩溃,不像是业务单纯把 CPU 或内存打满;更像是 KVM 虚拟机环境下,内核 6.8.0-124-generic、虚拟磁盘 I/O、ext4 journal commit、Docker 日志写入、journald 写盘、UFW 日志刷屏共同叠加后触发的系统级 soft lockup。
真正根因可能在几处之间:
- 虚拟化层
- 宿主机调度
- 存储后端
- 内核 bug
- 日志写入链路放大
生产事故很多时候没法给出实验室级别的根因证明。我能做的是根据证据把最可能的链路拆出来,然后把每个会放大故障的点都压下去。
第一件事:先把日志降下来
我先做的不是重启完就睡觉,而是处理日志。
具体做了这些:
- 关闭 UFW logging,避免公网扫描继续刷 kernel log 和 journald。
- 限制 journald 日志体积。
- 将 journald 改成
Storage=volatile,主要写入/run内存日志。 - 关闭 journald 转发到 syslog,减少重复写入。
Storage=volatile 有代价:重启后历史日志会少一些。
但在这次场景里,我更在意机器别再卡死。既然 journald 写盘路径疑似参与了问题,就先让它少碰磁盘。
第二件事:处理 Docker 日志
Docker daemon 加了日志轮转:
1 | { |
这里有个坑:Docker daemon 的日志配置通常要容器重建后才会完整生效。
所以我还给已经运行中的容器加了 logrotate 兜底,并把那份约 1.2G 的 sub2api JSON 日志截断到 KB/MB 级别。
这不是为了省那一点磁盘空间,而是为了减少巨型日志文件继续参与写入、扫描、同步的机会。
第三件事:让机器别半死不活挂着
系统级卡死最怕的不是重启,而是一直半死不活。
应用挂了,守护进程可能还能拉起来;容器挂了,Docker 可能还能重启。但内核态卡住时,上层很多自愈逻辑都没机会执行。
所以我打开了这些参数:
1 | kernel.softlockup_panic=1 |
意思很直接:
- soft lockup 触发 panic。
- hung task 触发 panic。
- panic 后 30 秒自动重启。
- 开启 NMI watchdog。
- 整机 OOM 时自动恢复。
100% 防止 soft lockup 不现实,尤其在云服务器 / KVM 场景。更现实的目标是:少触发,触发后快点回来。
第四件事:重新划容器资源边界
这台机器基本只跑 sub2api、Postgres 和 Redis,所以资源不是要压死,而是要给业务足够空间,同时给系统留余量。
| 服务 | 内存 | CPU | PIDs |
|---|---|---|---|
sub2api |
10G | 7 | 8192 |
postgres |
4G | 3 | 2048 |
redis |
1G | 1 | 1024 |
这个配置的目的不是限制业务,而是防止异常状态下某个容器把整机资源、进程数或调度压力一起拖垮。
第五件事:降低 healthcheck 频率
之前 Postgres / Redis healthcheck 是 10 秒一次。
平时没问题。但系统抖动时,Docker 不断创建 exec healthcheck,会继续给 dockerd / containerd 增加压力。
所以我把 Postgres / Redis healthcheck 从 10 秒一次降到 60 秒一次。
健康检查不是越频繁越好。在故障现场,它也可能添乱。
第六件事:加巡检和自愈
我新增了一个 systemd timer,每 5 分钟跑一次巡检脚本。
它主要检查:
systemd-journald是否 active,不正常就重启。- Docker JSON 日志是否超过阈值,超过就截断。
- UFW logging 是否被重新打开,如果打开就关掉。
- 磁盘和 inode 使用率。
- 最近 10 分钟内核是否出现
soft lockup、hung task、I/O error。 sub2api /health是否正常,连续失败 3 次就拉起 compose stack。
这不是银弹,但至少能把一部分“半夜手动救火”的动作,变成系统先自救一次。
第七件事:准备切到 HWE virtual 内核
当前故障发生在:
1 | 6.8.0-124-generic |
我考虑过临时回退到:
1 | 6.8.0-57-generic |
但这个版本太旧,不适合长期生产。
最后选择安装 Ubuntu 24.04 的 HWE virtual 内核:
1 | linux-virtual-hwe-24.04 |
并设置 GRUB 下次启动默认进入:
1 | 6.17.0-35-generic |
目前没有在高峰期主动重启,因为重启本身也会影响用户。内核已经装好,等业务低峰重启后生效。
如果底层确实跟内核版本、虚拟化或存储路径有关,只清日志只能算止血,不能算完整修复。
现在的状态
目前修复后的状态:
systemctl --failed: 0 failed unitssystemd-journald: activesub2api/postgres/redis: 全部 healthysub2api /health: 返回{"status":"ok"}- Docker 日志:已控制在 MB 级别
- 根分区和
/boot空间:正常 - 下次重启:进入
6.17.0-35-genericHWE 内核
同时,用户侧的处理也已经开始做:
- 受影响期间降低倍率。
- 给受影响用户补发额度。
- 发放优惠券,抵消这几天不稳定带来的体验损失。
这些补偿解决不了技术问题,但这是服务出问题后该有的态度。
这次给我的几个提醒
第一,AI 中转站这种业务,用户体感比后台原因重要。
你后台可以解释是内核、是服务商维护、是虚拟磁盘 I/O,但用户感受到的就是不能用。所以技术复盘要做,补偿也要做。
第二,服务器“卡死”不一定是应用 CPU / 内存打满。
如果 VNC 里已经看到 watchdog: BUG: soft lockup,排查层级就要下沉到内核态。
第三,journald 启动失败不一定是 journald 本身坏了。
它可能只是底层 I/O 或内核卡住后,第一个被你看到的受害者。
第四,Docker JSON 日志和 UFW 日志刷屏,真的会放大故障。
日志不是越多越安全。没有轮转、没有限流、没有降噪的日志,在系统抖动时会反过来参与事故。
第五,生产事故别只停在“重启一下”。
这次真正有价值的修复是:
- 日志降压
- Docker 日志轮转
- journald volatile
- watchdog 自动恢复
- 容器资源规划
- healthcheck 降频
- 定时巡检自愈
- 切换更合适的 virtual / HWE 内核
最后总结一句:
这次 AI 中转站连续故障,不是一个组件单独坏了,更像是一条系统链路被压到极限后的连锁反应。
后面我会继续观察新内核生效后的稳定性,也会继续把日志、监控和补偿机制补齐。服务做久了就会发现,稳定性不是一句“已经修复”就结束的事,它靠的是每次事故后把容易再次出问题的地方一点点堵上。
 wechat
wechat alipay
alipay